Update: Links to my talk Recording & Slides
A love letter to Everything Open!
Update: Links to my talk Recording & Slides
A love letter to Everything Open!
As our machine learning, data engineering, and artificial intelligence systems evolve, adapt, and learn, so too must we!
The intersection of the twin revolutions of Agile and Open Source Software development methodologies is a fascinating place. These movements are changing the world, and they have more in common than sets them apart. However the differences are fascinating and fundamental, and we are only starting to respectfully learn from each other.
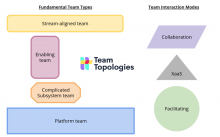
Over the past 3 days, I took part in Team Topologies immersion sessions.
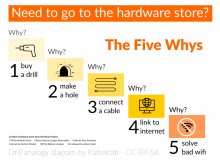
Imagine you work in a hardware store. You notice a customer puzzling over the vast array of electric drills.
She turns to you and says, I need a drill, but I don’t know which one to pick.
You ask “So, why do you want a drill?
“To make a hole.” she replies, somewhat exasperated. “Isn’t that obvious?”
“Sure,” you might say, “But why do you want to drill a hole? It might help us decide which drill you need!”
"Oh, okay," and she goes on to describe the need to thread cable from one room, to another.
Update: Video of this talk is now available.
Communication is a skill most of us practice every day.
Often without realising we're doing it.
Rarely intentionally.
A couple of days ago I found myself describing how to estimate the size of a story. It was coming out in my own words, without references. It felt... right.
One agile approach for "sizing" up a task is to use a relative scale to describe a mixture of effort, complexity and uncertainty.
Last week I completed scrum master training... and now need to prepare for the exam to become a certified scrum master. This makes me a scrum padawan at this point. Right?
So... first up, commit to heart the key statements of the Agile Manifesto.